
Scientific research involves striving for knowledge, which requires complicated investigation, extensive statistical assessment, and detailed information collection. Attaining precise and trustworthy outcomes is essential in research. This is why researchers aim to design studies and experiments that can examine and isolate the particular variables they need to investigate.
However, some concealed elements can hide the actual relationships between variables and skew conclusions. These elements are called confounding variables, which are elusive and could slant outcomes and impede the pursuit of truth. Let’s have a look at the definition of confounding variables.
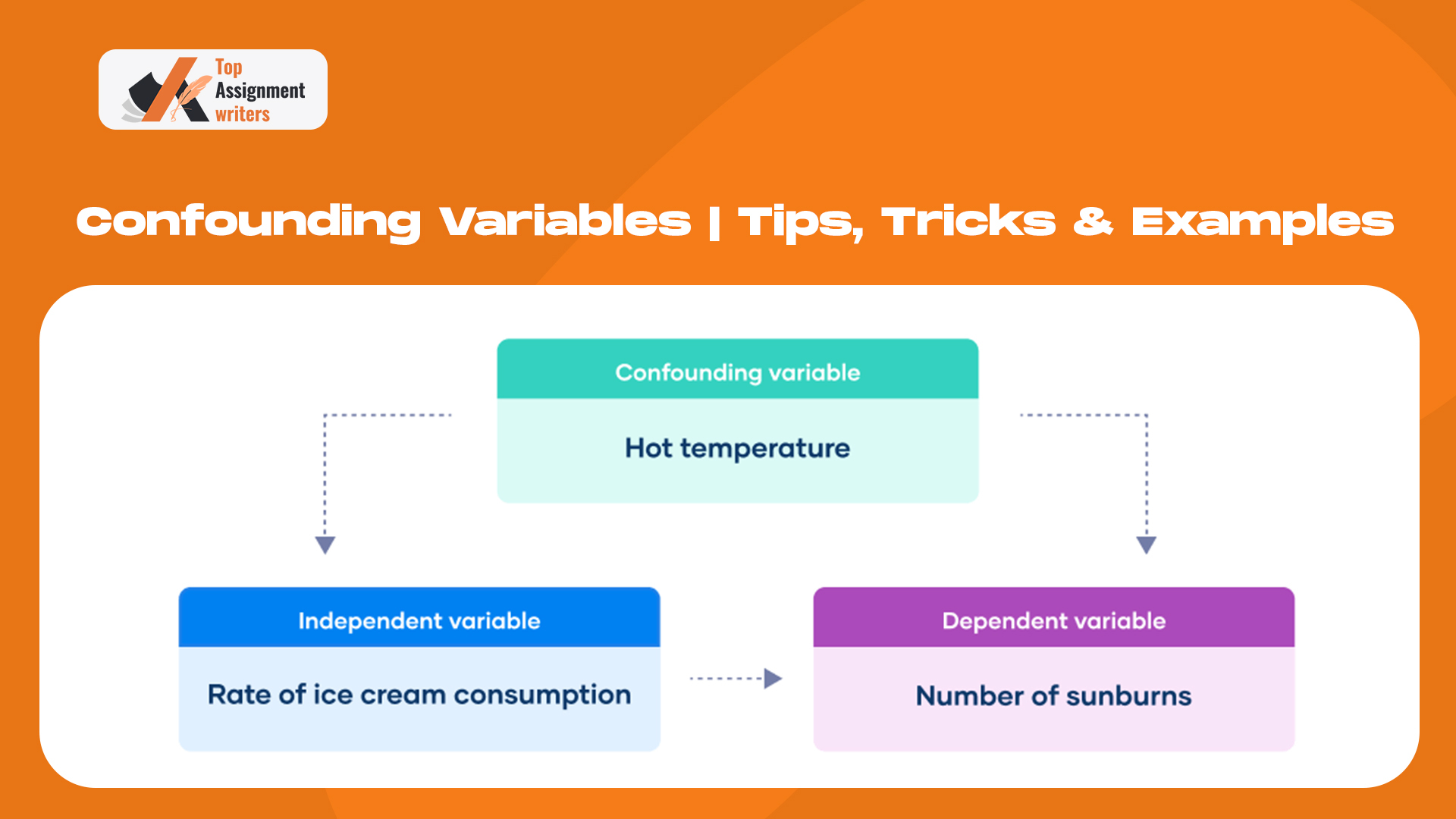
What are Confounding Variables?
In research that examines a possible cause-and-effect relationship, a confounding variable acts as an unmeasured third variable that affects both the supposed cause and outcome.
It’s crucial to acknowledge possible confounding variables and consider them in research experiments to guarantee the validity of results. These variables are lurking variables, confounding factors, or confounders. They are not the variables that research primarily focuses on. However, they serve as an external aspect relevant to a study’s dependent and independent variables. There are two conditions for a variable to be counted as a confounding variable.
- It should correlate with the independent variable. It might be a causal relationship, but that isn’t necessary.
- A confounding variable should have a causal relationship with the dependent variable.
Example of A Confounding Variable
A researcher gathers data on coffee drinkers and heart disease. They find that higher coffee consumption is linked with a higher probability of heart disease. Does that mean coffee consumption leads to heart disease?
In this example, the confounding variable is smoking. Here, heart disease is a dependent variable, and coffee drinking is an independent variable. Smoking may cause heart disease, not coffee, but people who drink more coffee might also engage in more smoking than non-coffee drinkers. Moreover, some researchers have found coffee drinking to positively impact cardiovascular health and prevent dementia.
Why Are Confounding Variables Important?
People who perform research must consider confounding variables to check the internal credibility of their research outcomes. If they don’t do that, their research might not show the real relationship between the variables they are focused on.
For example, their study may reflect a wrong cause-and-effect relationship between the variables they are researching. Because the confounder causes the impact they analyze. And not by the primary independent variable they are studying.
Research Example
A study that aims to examine the effect of students’ IQ on their reading capability. It may be found that children with higher IQs have better reading ability. However, the families from which those children belong may be a confounding variable. Because children from affluent families might have more access to educational resources and books. The researchers must take into account the socio-economic status of the students they are studying otherwise they may find a causal relationship that doesn’t exist.
Overestimation
In some cases, confounding variables might not stop a researcher from rightly detecting a causal relationship. However, they may lead to under- or overestimation of the effect of the independent variable on the dependent variable.
Example: Overestimation
A researcher may find that more jobless people in a specific county were suffering from mental health disorders than the employed population. Does that mean unemployment leads to poor mental health?
Here, they might be ignoring the fact that jobless people have less money to eat nutritious food, which is also essential for good mental health. Also, they may be getting more screen time, which correlates with poor mental health.
So, they may overestimate the relationship between unemployment and poor mental health.
How to Decrease the Effect of Confounding Variables?
You can reduce the effect of confounding variables using different methods. These methods can be used to analyze any subject (animals, humans, chemicals, plants, etc). Each method poses some benefits and downsides.
Restriction
This method limits a treatment group by only studying participants with similar values of possible confounders. The values are the same for the study participants, so they cannot link with the independent variable. They, therefore cannot confuse the causal relationship, which is the aim of the research.
Example: Restrictions
You aim to research the impact of a keto diet on weight loss. But you know that other factors affect weight loss, such as sex, age, exercise intensity, level of education, and the diet somebody follows. So, you limit your subject sample to 35-year-old females with master’s degrees. Who perform moderate-intensity cardio exercise for 60 to 90 minutes per week.
Pros
- Comparatively easy to apply
Cons
- Limits your sample a lot
- You may not account for other possible confounding factors
Matching
This method involves choosing a comparison sample that matches the treatment group. Every subject in the comparison sample must have a counterpart in the treatment sample. With similar values of possible confounding variables but different independent variable values.
It enables you to remove the possibility of differences in confounders leading to variation in results between the comparison and treatment groups. If you consider any possible confounding factors, you could thus deduce that the difference in the independent variable should be the reason for variation in the dependent variable.
Example: Matching
In your research on keto diet and weight loss, you will include subjects matching age, education level, sex, and exercise intensity. It helps you match up a broader array of subjects — your treatment group includes males and females of various ages with different education levels.
You match every subject on a keto diet with another subject with the same traits who is not following the diet. It means for every 35-year-old moderately educated woman who is on a keto diet. You find another 35-year-old moderately educated woman who is not. Then, you compare their weight loss. You use the same procedure for every subject in your treatment sample.
Pros
- You can include more subjects than the restriction method
Cons
- It may be hard to apply as you require pairs of subjects that have similar possible confounding factor.
- There might be other confounders that you cannot match on
Statistical Control
If you have gathered information, you may add the potential confounding variables as control variables in the regression analysis. Moreover, it will allow you to control the effect of the confounder.
If the possible confounding factor has an impact on the dependent variable. It will reflect in the outcomes of the regression and enable you to separate the effect of the independent variable.
Example: Statistical Control
So, first, you will gather information about keto diets and weight loss from a variety of subjects in your regression analysis. Then you consider exercise levels, age, sex, and education as control variables. As well as the type of diet each participant follows as the independent variable.
It enables you to separate the effect of the diet selected from the impact of these other four factors on weight loss in your regression.
Pros
- Convenient to apply
- You can implement it after data collection
Cons
- You can only account for variables that you monitor directly but other confounders you haven’t controlled may remain
Randomization
In this method, you randomize the values of the independent variable to reduce the effect of confounding factors. For example, if you assign a few of your subjects to a treatment group and others to a control group, you can randomly allocate subjects to each group.
The randomization method assures that with a large enough group, all possible confounders (even those you cannot directly examine in your research) have the same average value between various groups. As all the confounding variables are the same for all groups, they have no association with your independent variable and therefore, can’t invalidate your research.
As randomization enables you to consider all possible confounders which is almost impossible to do using any other method, it is typically known as the optimal technique to minimize the effect of confounding factors.
Example: Randomisation
You collect a large set of participants to take part in your research on weight loss. You haphazardly choose fifty percent of them to follow a keto diet and the other fifty percent to go on with their regular eating habits.
Randomization ensures that both the keto diet group and the control group will have the same average education, exercise levels, and age as well as the same average values on other traits that you haven’t measured.
Pros
- It lets you consider all potential confounders, including ones that you might not examine directly
- Researchers consider it the best technique to reduce the influence of confounding factors
Cons
- It is the toughest to implement
- You must carry it out before starting data collection
- You should guarantee that only subjects in the treatment and not control category get the treatment
Bottom Line
Confounding variables may alter the correlation between dependent and independent variables in research. Thus, identifying, controlling, and acknowledging them is key to guaranteeing the precision and viability of study results. The pursuit for the right information is not exclusively described by the variables someone tries to examine but also by the carefulness with which they acknowledge the intricacies linked with the confounding variables. It would develop a clearer reporting of research that is trustworthy and well-founded.